
今天繼續努力,昨天分享了yolo v1的一些心得後跑去試著實做看看,想說至少讓他可以開始訓練,但好像沒那麼容易,一定是哪裡出了問題,所以今天沒東西可以分享。
因此想說接下來開啟一個新的章節,預計接著把deep lab v1 v2 v3的paper 看過一次,然後好好了解一下原理,順便接著繼續做yolo v1,看看能不能成功吧。最近真的是忙到爆,但是也很充實,要一直加油了!
SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS:
首先什麼是semantic segmentation在上一篇有簡單提到一下,顧名思義就是語義切割,但我想這樣會誤導很多人,以為是不是什麼chat bot在用的,至少我一開始看中文翻譯也是被混淆一下,但semantic的確是語義的意思,但是是指image pixels的語義,也就是說每一個pixel究竟屬於哪一個label. 舉例來說:
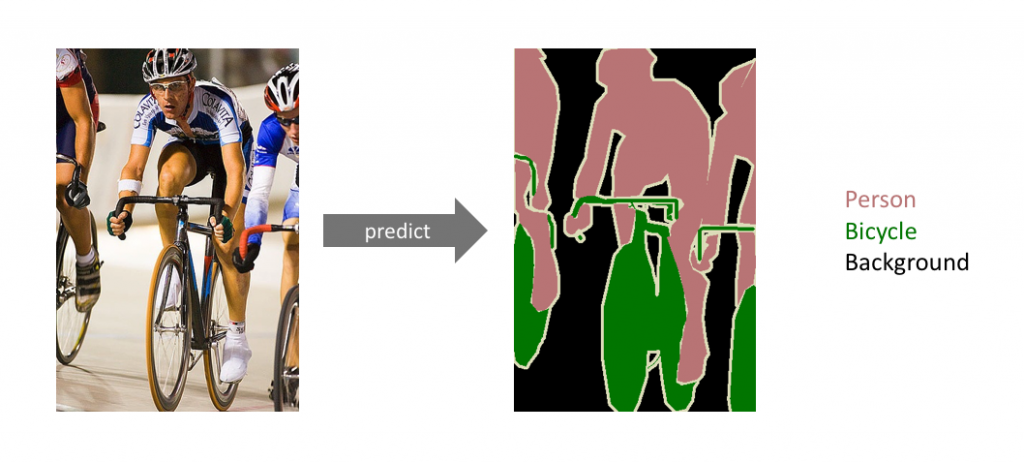
在這張圖片中你想要把腳踏車,腳踏車騎士,背景都切割開來,要做到這樣就必須每個pixel都assign 一個label,並且把每一個pixel的位置和分類都成功做好,才會實現這樣的結果。因此這就是semantic segmantation, 在這之前我已經讀了一樣是用在這領域的另一個方法FCN(Fully convolutional network),而deeplab 這個方法似乎是目前最厲害的,因此我想來看看,順便學習一下。
跟著菜鳥讀吧:
摘要:
DCNN(deep convolutional neural network)在電腦視覺上展現驚人的成果,不管是image classification 或是object detection都有其一席之地。而這篇的方法結合DCNN和機率圖像模型(probabilistic graphical models)來實現pixel-level classification(其實就是semantic segmentation)。單靠DCNN在最後一層時會發現沒有足夠精準的位置資訊(對於pixel level classification這樣的任務而言),我想應該是因為pooling吧? (猜測,之後看下去), 但是DNCC可以負責high level的訊息(more deep more high level info)。而這篇利用fully connected Conditional Random Field (CRF)結合在DCNN的最後一層layer.解決了位置訊息不夠的缺點。 並在PASCAL VOC-2012 semantic image segmentation task達到了71.6%的準確度。
剩下的明天接著繼續深入!
